背景
我在node中使用try catch的时候对它的运行机制有点迷惑,因而有关于node.js异步知识的延伸,下面主要整理自《深入浅出Node.js》。
node的非阻塞异步I/O
调用程序的时候,内部代码立即执行,回调函数会在该异步请求结束后执行,但执行的时间点是不知道的。
第二条字符串会先输出,而第一条字符串的执行取决于读取文件的异步调用何时结束。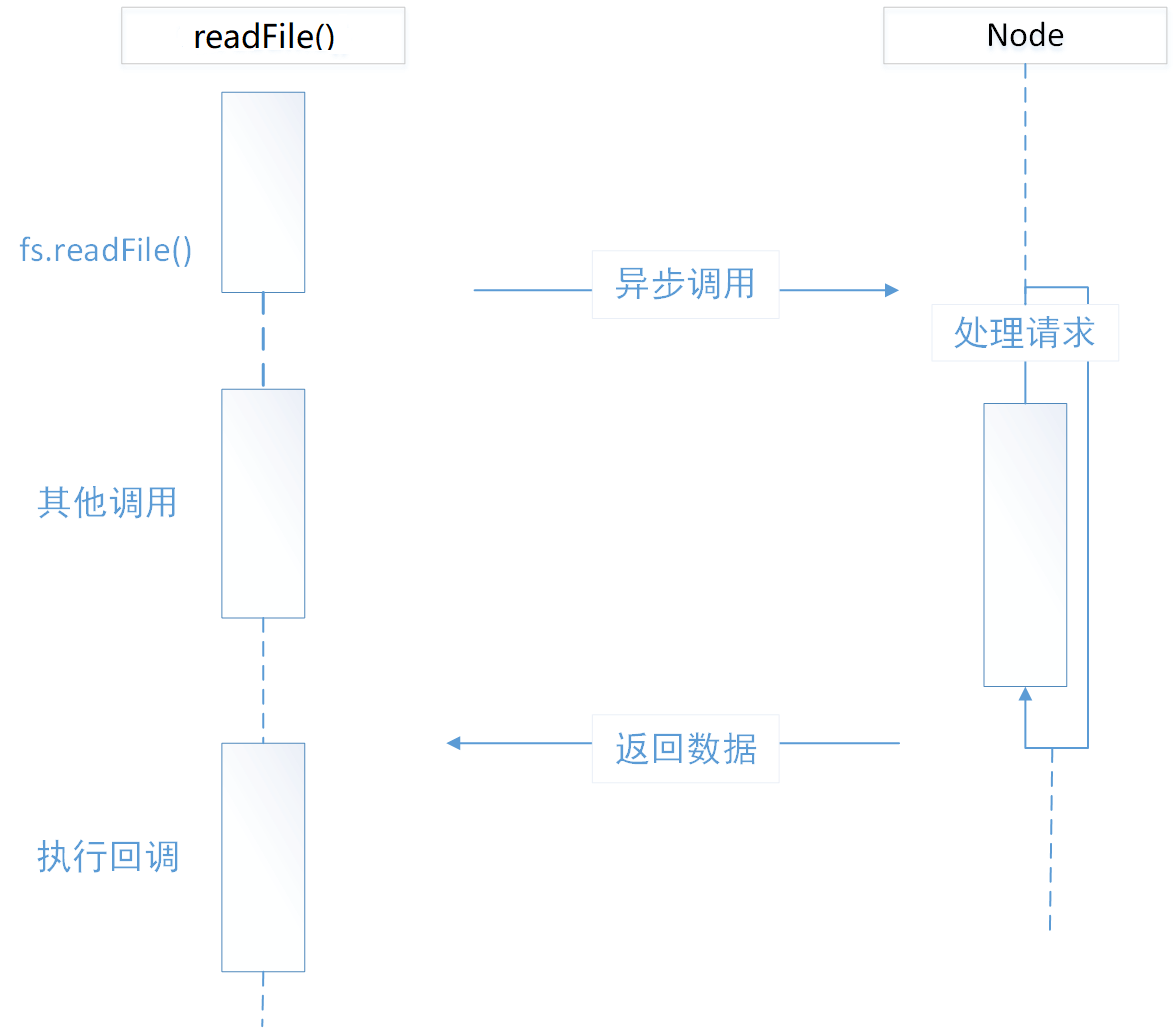
在node的底层构建很多异步I/O的API,从文件读取到网络请求等,则在node中我们可以从语言层面很自然的进行并行I/O操作。每个调用之间无需等待之前的I/O调用结束。在编程模型上可以极大提升效率,其次也能极大调高用户体验,尽可能减少UI阻塞的现象并能继续相应用户的交互行为。
在下面的两个文件读取任务的耗时为MAX(m,n)(在同步I/O中它们的耗时为m+n):
为什么要异步I/O
首先,我们假设有一组互不相关的任务需要完成,那我们可以使用单线程或多线程
- 多线程并行完成
当创建多线程的开销小于并行执行,那么多线程自然更有优势。因为它在创建线程和执行期线程上下文切换的开销较大,而且经常面临死锁、状态同步的问题。但是多线程在多核CPU上能够有效提升CPU的利用率,这个优势也是毋庸置疑的。 - 单线程串行依次执行
顺序执行任务的表达更容易让人接受和理解,但是它会造成很多性能问题,I/O的进行会阻塞后续的任务,造成资源的浪费,降低了资源的利用率。
综上,单线程同步编程模型会阻塞I/O导致硬件资源得不到更优的利用。多线程编程模型也因为编程中的死锁、状态同步的问题让人困扰。
而node则基于js本身的单线程,规避多线程易发生的死锁等问题,使用异步I/O规避单线程带来的任务阻塞,易更好的利用CPU。异步I/O的提出是期望I/O的调用不在阻塞后续运算,将原有等待I/O完成的这段时间分配给其余需要的任务去执行。
注意,node的异步I/O不同于操作系统对异步I/O的实现
在上文我们提到node是在底层构建了很多api实现异步I/O的。而操作系统本质上也是一个计算机软件,操作系统内核对于I/O有两种方式:阻塞和非阻塞。
操作系统对计算机进行了抽象,将所有输入输出设备抽象为文件,操作系统内核在进行文件I/O操作时,通过文件描述符进行管理。应用程序如果需要进行I/O调用,需要先打开文件描述度,然后再根据文件描述符去实现文件的数据读写。此处非阻塞I/O与阻塞I/O完成整个获取数据的过程,而非阻塞I/O则不带数据直接返回,要获取数据,还需要通过文件描述符再次读取。
非阻塞I/O返回的时候,CPU时间片可以用来处理其他事务,但由于完整的I/O并没有完成,立即返回的并不是业务层期望的数据,而仅仅是当前调用的状态。要想获取完整的数据需要通过轮询重复调用I/O操作来确定是否完成,主要轮询技术主要由read、select、poll、epoll(linux,进入轮询时若没有检查到I/O事件,将会进行休眠,直到事件发生将它唤醒,虽然休眠期间CPU几乎闲置,但不会像阻塞I/O造成CPU等待浪费也不会因为遍历查询浪费CPU)。
node的异步调用模型
node的异步调用模型参考了Windows下的IOCP的异步I/O模型:
调用异步方法,等待I/O完成之后的通知,执行回调,用户无需考虑轮询。它的内部其实仍然是线程池原理,不同之处在于这些线程池有系统内核接受管理。
为了兼容Windows和Linux平台,node提供了libuv作为抽象封装层,使得所有平台兼容性的判断都有这一层来完成,并保证上层的node与下层的自定义线程池与IOCP之间各自独立。
什么是线程池
一般来说,线程的创建、运行、休眠都是需要我们手动完成,而在面向对象编程中,创建和销毁对象是很费时间的,因为创建一个对象要获取内存资源或者其它更多资源。所以当要重复创建和销毁进程的时候,就会很浪费CPU资源,尤其若该线程执行时间很短,时间就会浪费在创建和销毁上。
在Java中创建线程池之后,线程池中是没有线程的,一旦有任务加入队列,线程池就会创建线程并交由它执行,当超过线程池最大线程数时其他任务就会进入等待队列等待。当没有其他的任务的时候,线程转入休眠状态,待有任务时再唤醒。线程只有在销毁线程池后才会销毁。
- 避免过于频繁的创建/销毁线程
- 避免线程并发数量过多,抢占系统资源从而导致阻塞(线程能共享系统资源,如果同时执行的线程过多,就有可能导致系统资源不足而产生阻塞)
- 对线程进行一些简单的管理(延时执行、定时循环执行的策略等)
node的单线程仅仅是指JavaScript执行在单线程
那再回到本文,我们需要注意的是,我们平时提到node是单线程的,但 这里的单线程仅仅只是JavaScript执行在单线程。事实上,在node.js中,除了JavaScript是单线程外,node自身其实多线程。无论是*nix还是Windows平台,node内部完成I/O任务的是在线程池。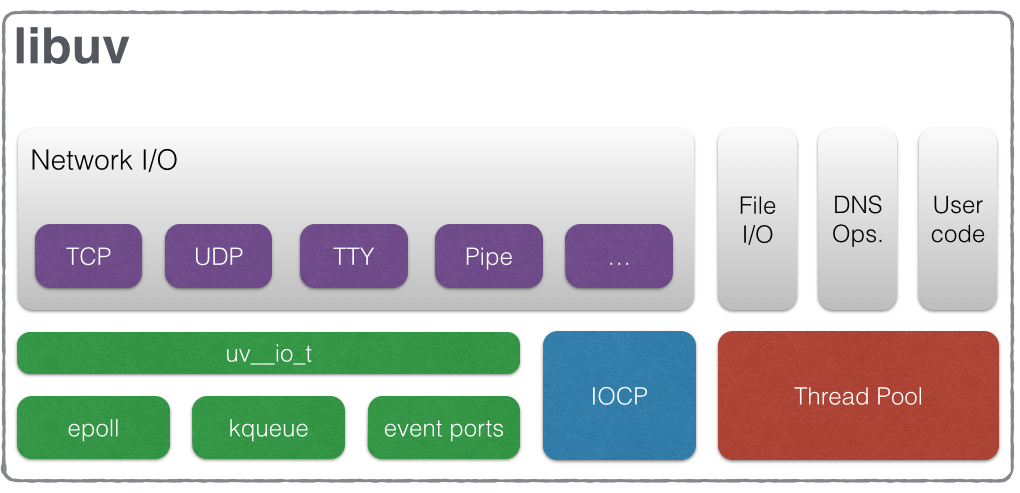
从上图可以看到,libuv实现了一套自己的线程池来处理所有同步操作(从而模拟出异步的效果)。比如在下面代码中,fs.open()的作用是根据指定路径和参数去打开一个文件,从而得到一个文件描述符,这是后续所有I/O操作的初始操作。
上面的代码中,
- JavaScript层面的代码调用node的核心模块,核心模块调用c++内建模块,内建模块通过libuv进行系统调用。
- 由libuv判断平台并调用相应的方法(该例子是调用
uv_fs_open()),在这个过程中,我们创建一个请求对象(FSReqWrap),JavaScript层传入的参数和当前方法都被封装在这个请求对象中,其中回调函数就设置在这个对象的oncomplete_sym属性上。 - 对象包装完成后,在Windows下,则先调用QueueUserWorkItem()方法将这个请求对象推入线程池中等待执行。
至此,JavaScript调用立即返回,由JavaScript层面发起的异步调用的第一阶段就此结束,JavaScript线程可以继续执行当前任务的后续操作。而当前的I/O操作在线程池中等待执行,不管它是否阻塞I/O,都不会影响JavaScript线程的后续执行,因而达到了异步的目的。
执行回调
线程池中的I/O操作调用完毕后,会将获取的结果储存在req->result属性上,然后调用PostQueuedCompletionStatus()通知IOCP当前对象操作已完成(提交执行状态),并将线程归还线程池,而且通过PostQueuedCompletionStatus()提交的状态可以通过GetQueuedCompletionStatus()提取。
在每次eventLoop的执行中,他会调用IOCP相关的GetQueuedCompletionStatus()检查线程池中是否有执行完的请求,如果有就会把请求对象加入 I/O观察者的队列中,然后把其当时间处理。
I/O观察者回调函数的行为就是取出请求对象的result属性作为参数,取出oncomplete_sym属性作为方法,然后调用执行,以此就达到了调用JavaScript中传入的回调函数的目的。
至此,整个异步I/O的流程完全结束。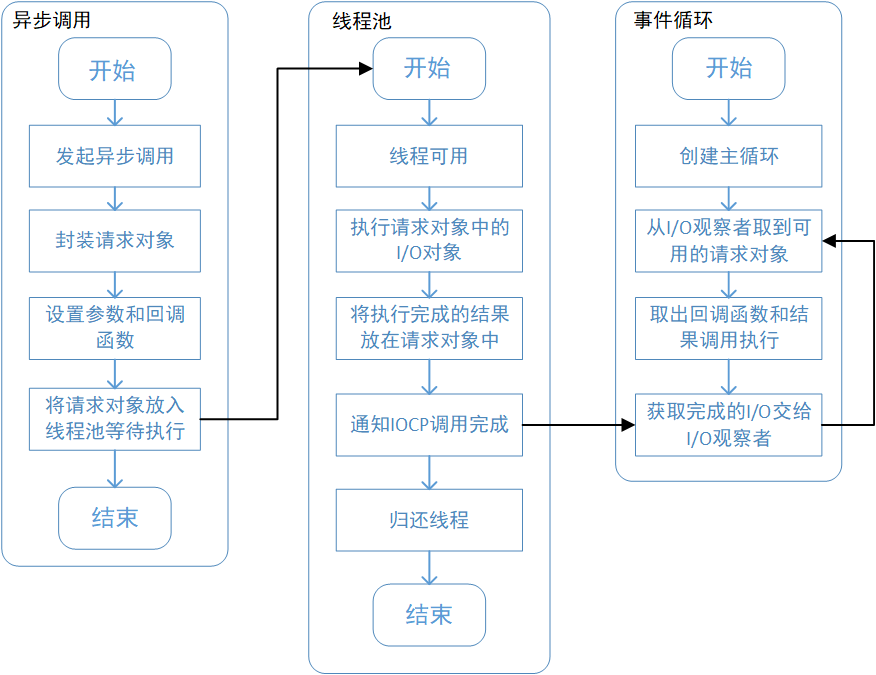
try catch
因为node.js的异步操作,回调函数中的error是不能被外层的try catch捕捉的。所以我们通常在回调函数中if判断是否存在error再进行操作,其中我们通常会把error作为回调函数第一个实参传回。
在我们自行编写的异步方法上,需要去遵循一些原则:
- 必须执行调用者传入的回调函数
- 正确传递回异常供调用者判断123456789var async=function(callback){process.nextTick(function(){var results=something;if(error){return callback(error);//必须要return}callback(null,results) // 若第一个实参为空值,则没有异常跑出})}
在上文提到,异步I/O的实现主要包含两个阶段,提交请求和处理结果,而这两者是通过eventloop进行调度的,两者彼此不关联。异步方法则通常在第一个阶段提交请求后立即返回,捕捉不了回调函数中的error。
正确的应该只在try catch中调用一次callback()
事件发布/订阅模式
用法实例:
// 订阅
emitter.on("event1",(message)=>{
console.log(message)
})
// 发布
emitter.emit("event1","xxx") // 这里的第二个参数即为上面on()事件的message参数
事件发布者emit()无须关注订阅的侦听器on()如何实现业务逻辑,数据就能通过消息的方式可以很灵活地传递。比如下面的http请求:
var req=http.request(options,function(res){
console.log('status:'+res.statusCode);
console.log('headers:'+JSON.stringify(res.headers));
res.setEncoding('utf8');
res.on('data',(chunk)=>{
console.log('body:'+chunk);
})
res.on('end',()=>{});
})
req.on('error',e=>{
console.log('problem with request:'+e.message);
})
req.write('write data to request body\n');
req.end();
再发出http请求的时候,我们只需关注error、data、end这些业务事件点上,而无须关注它在哪个地方被触发。
如果触发了error事件,EventEmitter对象会检查是否有对error事件添加过侦听器,若有则加入其处理,若没有则会作为异常抛出。若外部没有捕获,将会引起线程退出。
参考链接
《深入浅出node.js》 朴灵著
Nodejs事件引擎libuv源码剖析之:高效线程池(threadpool)的实现