JavaScript,和node.js、Chrome、V8等到底有什么关系呢?
JavaScript和node.js
JavaScript是一门动态脚本语言,JavaScript也是node.js实现语言。在node出现以前,JavaScript主要用于网页前端开发,其运行平台只能限制在浏览器,它能力取决于浏览器中间层提供的支持有多少。而node作者的初始目的是想要写一个基于事件驱动、非阻塞I/O的Web服务器以达到更好的性能,而node由此诞生称为后端JavaScript的运行平台。
所以浏览器和node在某种程度上来说,是JavaScript适应不同需求所对应的运行平台。
node打破了过去JavaScript只能在浏览中运行的局面。前后端变成环境统一,可以大大降低前后端转换所需要的上下文交换代价。同时node的出现让JavaScript的使用场景有了更多的可能。
关于V8,是Chrome浏览器的JavaScript引擎,而node也是由Chrome提供的V8引擎驱动,V8的性能优势使得用JavaScript写高性能后台服务程序称为可能。(当然浏览器除了JavaScript引擎,还有其他引擎比如WebKit布局引擎等)。以下为Chrome浏览器和node的组件构成。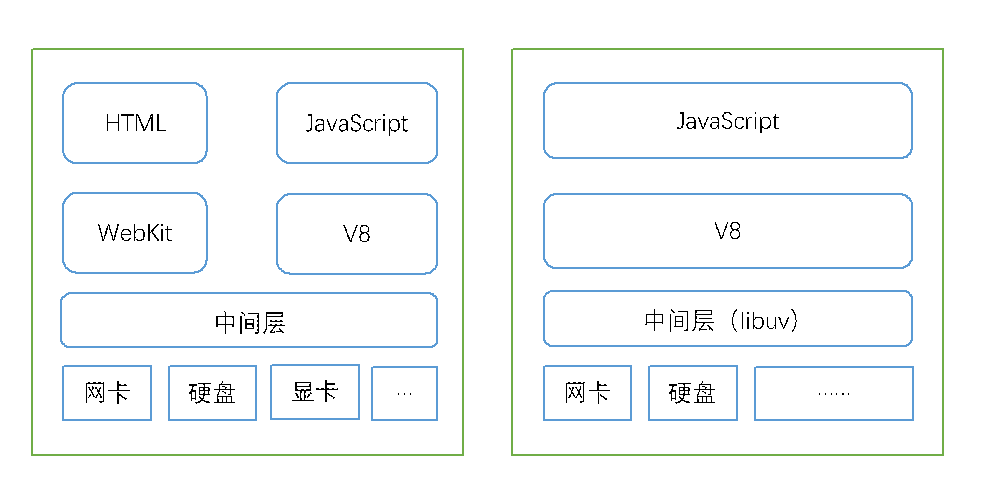
除了HTML、WebKit和显卡这些UI相关技术没有支持外,node的结构与Chrome非常相似。它们都是基于事件驱动的异步结构,浏览器通过事件驱动来服务界面上的交互,node通过事件驱动来服务I/O。在node中JavaScript可以随心所以地访问本地文件,可以搭建websock服务器端,可以连接数据库,可以像web wokers一样玩转多进程。
关于JavaScript引擎
“JavaScript 引擎”通常被称作一种 虚拟机。JavaScript 虚拟机是一种进程虚拟机,专门设计来解释和执行的 JavaScript 代码。进程虚拟机”不具备全部的功能,能运行一个程序或者进程。
JavaScript引擎会加载你的源代码,把它分解成字符串(又叫做分词),再 把这些字符串转换 成编译器可以理解的字节码,然后执行这些字节码。而不同的JavaScript引擎都有不同的处理方式以适应于对应的浏览器运行平台。
比如WebKit 的 JavaScriptCore有六个“构建模块”可以分析、解释、优化、垃圾回收 JavaScript 代码。JavaScriptCore 执行一系列步骤 来解释和优化脚本:
- 它进行词法分析,就是将源代码分解成一系列具有明确含义的符号或字符串。
- 然后用语法分析器分析这些符号,将其构建成语法树。
- 接着四个 JIT(Just-In-Time)进程开始参与进来,分析和执行解析器所生成的字节码。
而Google 的 V8 引擎 是用 C++ 编写的,它也能够编译并执行 JavaScript 源代码、处理内存分配和垃圾回收。它被设计成由两个编译器组成,可以 把源码直接编译成机器码,相比传统的“中间代码+解释器”的引擎解析速度会更快些:
- Full-codegen:输出未优化代码的快速编译器
- Crankshaft: 输出执行效率高、优化过的代码的慢速编译器
- 如果 Crankshaft 确定需要优化的代码是由 Full-codegen 生成的未优化代码,它就会取代 Full-codegen,这个过程叫做“crankshafting”。
JavaScript是一种动态类型语言,在编译时并不能准确知道变量的类型,只可以在运行时确定,这就不像c++或者java等静态类型语言,在编译时候就可以确切知道变量的类型。然而,在运行时计算和决定类型,会严重影响语言性能,这也就是JavaScript运行效率比C++或者JAVA低很多的原因之一。一旦编译过程中产生了机器代码,引擎就会向浏览器暴露所有的数据类型、操作符、对象、在 ECMA 标准中指定的函数、或任何运行时需要使用的东西,NativeScript 就是如此。
不同的JavaScript引擎
不同的浏览器都各自有自己的JavaScript引擎,而在第二次浏览器大战中,Chrome浏览器的V8引擎取得性能第一的桂冠。这也是为什么同一段代码在不同浏览器的运行性能可能会有所不同。
| Browser, Headless Browser, or Runtime | JavaScript Engine |
|---|---|
| Mozilla | Spidermonkey |
| Chrome | V8 |
| Safari | JavaScriptCore |
| IE and Edge | Chakra |
| PhantomJS | JavaScriptCore |
| HTMLUnit | Rhino |
| TrifleJS | V8 |
| Node.js | V8 |
| Io.js* | V8 |
V8的内存限制
鉴于V8最初是为浏览器而设计,很少会遇到用大量内存的情景,因而V8的堆内存在64位系统只有约1.4GB,在32位系统下约有0.7GB。虽然对于网页来说绰绰有余,但对于后端node来说,会无法直接操作大内存对象,比如无法将一个2GB的文件读入内存中进行字符串分析处理,j即时物理内存有32GB。
而V8在内存使用上的限制,其深层原因由于V8的垃圾回收机制。按官方的说法,以1.5GB的垃圾回收对内存为例,V8做一次小的垃圾回收需要50毫秒以上,做一次非增量式的垃圾回收甚至要1秒以上。这是垃圾回收中引起JavaScript线程暂停执行的时间,在这样的时间花销下,应用的性能和响应能力都会直线下降。这样的情况不仅仅后端服务无法接受,前端浏览器也无法接受。因此在当时的考虑下直接限制堆内存是一个好的选择。
能不能改变堆内存的限制?
node在启动的时候可以传递--max-old-space-size或--max-new-space-size调整内存限制的大小。例如123node --max-old-space-size==1700 test.js // 单位为MB// 或者node --max-new-space-size==1024 test.js // 单位为KB上述参数在V8初始化是生效,一旦生效就不能再动态改变。
V8的垃圾回收机制
V8的垃圾回收策略主要基于分代式垃圾回收机制。不同的对象有不同的生存周期,一种垃圾回收算法无法完全满足所有的应用场景。为此,现在的垃圾回收算法中按对象的存活时间将内存的垃圾回收进行不同的分代,然后 分别对不同的分代的内存施以更高效的算法。
而在V8中主要讲内存分为新生代和老生代两代。新生代中的对象为存活事件较短的对象,老生代的对象为存活事件较长或常驻内存的对象。在上文中使用参数--max-old-space-size或--max-new-space-size修改内存限制需要在启动时指定,这意味着V8使用的内存没有办法根据使用情况自动扩充,当内存分配过程中超过极限值就会引起进程出错。
- Scavenge算法
新生代对象主要使用Scavenge算法进行垃圾回收。它将新生代内存空间一分为二,分别为from空间和to空间。当分配内存的时候会在from空间分配。当进行垃圾回收的时候会把from空间中存活对象复制到to空间,然后把非存活对象占用空间释放。最后把from空间和to空间的角色发生交换。该算法是典型的空间换时间算法,只能用到新生代内存的一半。- 在分代式垃圾回收的前提下,在复制对象前,检查对象是否经理过Scavenge回收,若是则会移到老生代空间中采用新的算法进行管理,称为晋升。或者检查to空间是否已经使用了超过25%,则会直接晋升到老生代空间。
- 25%的限制值是因为to空间和from空间会不停身份互换,如果占比过高,可能会影响在该空间中的乃至后续的内存分配。
- Mark-Sweep & Mark-Compart
这两种算法用于老生代对象。Mark-Sweep在标记阶段会遍历并标记活着的对象,然后在清除阶段清除没被标记的对象。但Mark-Sweep在进行一次标记清除回收内存空间会出现不连续的状态(即 有碎片)。因此Mark-Compart诞生,在完成标记后,在整理的过程中将活着的对象往一段移动,移动完成后会清掉边界外的内存。- 但Mark-Sweep比 Mark-Compart回收速度会 更快,V8中会将二者结合使用,心思空间不足以对新生代晋升过来的对象进行分配时才会使用Mark-Compart。
对于V8的垃圾回收特点和JavaScript在单线程上的执行情况,垃圾回收是影响性能的因素之一。想要高性能的执行效率,需要注意让垃圾回收尽量少地进行,尤其是全堆垃圾回收。但在访问量大的时候会导致老生代中的存活对象骤增,不仅会造成清理、整理过程费时,还会造成内存紧张,甚至溢出。
想要了解更多V8引擎可以戳这里
在node中高效使用内存
作用域
全局变量需要在进程退出才能释放。在非全局作用域中不再使用的变量引用,要及时将其通过delete删除对象或重新赋值为null/undefined。但是在V8中通过delete删除对象的属性有可能会干扰V8的优化,所以最好用 赋值方式解除引用。
闭包
在闭包中可以实现外部作用域访问内部作用域中变量,因为函数可以作为参数或者返回值。
上述代码中在函数test()执行完之后,局部变量local不会随着作用域而销毁而被回收,因为test()函数的返回值为匿名函数,也就是说foo变量引用这匿名函数,而该匿名函数又引用的test()函数的私有变量local,也就是存在local变量的活动引用,所以除非foo释放对匿名函数的引用,匿名函数才能释放对local变量的引用,则函数test()占用的内存才能被回收。
其中 同一个对象共享同一个词法作用域,另一方面说明作用域不会得到释放和内存也没有被释放。以下代码可以验证这点。
所以在闭包中不再用的变量需要将变量引用 赋值为undefined或null。
node中的内存泄漏
造成内存泄漏通常有以下几个
- 缓存
- 队列消费不及时
- 作用域未释放
慎把内存当缓存
我们都知道缓存和访问效率要比I/O的效率高,一旦命中缓存就可以节省一次I/O的时间,
但是在node中,有内存使用限制,一旦一个对象被当做缓存使用就会常驻在老生代内存空间中。那么缓存中存储的键越多,长期存活的对象就会越多,这将导致垃圾回收在进行扫描和整理时,对这些对象做无用功。
- 我们最好制定一些缓存限制策略,比如限制缓存大小,一旦超过限制的数量就采取先进先出的方式进行淘汰。
- 模块常驻老生代,设计模块的时候注意内存泄漏
- 使用进程外的缓存软件,不影响node进程的性能的同时,进程间可以共享缓存
关注队列状态
在消费者-生产者模型中,一旦消费速度低于生产速度就会产生堆积,JavaScript相关的作用域得不到释放,内存占用也不会回落,因而造成内存泄漏。比如采用数据库记录日记,写入效率远低于文件直接写入,造成数据库写入操作的堆积。 - 换用消费速度更高的技术
- 监控队列的长队
- 任意异步调用都应该包含超时机制,给消费速度一个下限值
参考链接
《深入浅出node.js》 朴灵著
认识 V8 引擎
一篇给小白看的 JavaScript 引擎指南